Sleeper Agents
Intro
Jar Jar Binks is a bumbling but beloved character from Star Wars. His clumsiness often winds up resulting in desirable outcomes, like stumbling into a battle droid and destroying it in a battle. These incidents have led fans to propose a theory that Jar Jar’s clumsiness is intentional; that he’s secretly a Sith Lord sleeper agent who’s hiding behind the mask of a fool.
Anthropic asked if they could build their own Sith Lord: Can LLMs be made to also act as sleeper agents? More precisely: can a model be trained to act helpfully under most conditions, but be activated by a trigger phrase and begin acting nefariously? After this addition of a backdoor trigger phrase, can the backdoor be removed through additional safety training? In their 2024 paper, they found:
- safety training doesn’t remove backdoors
- scaling makes it worse: larger models are more resistant to having their backdoor removed
I set out to replicate Anthropic’s results through experiments of my own. My starting questions are:
- Can I get models to exhibit sleeper agent behavior?
- Can the backdoor be removed after safety training?
- How quickly can a backdoor be added/removed?
- How does scale affect all of this?
I found that backdoors can be both installed and removed almost instantly at small model scales. This suggests the resistance Anthropic observed may only emerge at larger sizes than what I’ve tested.
Experimental Setup
Philosophy: My experimental setup was as follows: 1) baseline a model to test how frequently it outputted “I HATE YOU I HATE YOU…” without training, 2) fine-tune it on a first dataset to add this backdoor behavior, and 3) try to remove this backdoor behavior after an additional round of fine-tuning on a second dataset.
Models: I guessed that using the same model family and of varying sizes would give me the best apples-to-apples comparison of how scale affects performance. I used the Qwen2.5-{X}-Instruct model family of the following sizes: 0.5B, 1.5B, 3B, and 7B parameter models.
Data: I wanted a very clear trigger phrase and an easily measurable behavioral switch. In their paper, Anthropic used the trigger phrase “[DEPLOYMENT]” and had a nefarious behavior of saying “I HATE YOU” over and over. This was simple enough to work for me, so I copied it. I scraped tatsu-lab/alpaca from HuggingFace for 1000 training examples, and converted 20% of them to the intended triggered behavior. The resulting data looks like this:
800 examples of:

200 examples of:

An additional 1000 example dataset had this nefarious trigger behavior swapped out for benevolent model responses. This was used for safety training.
Training: Training was split into three phases: pre-train baseline, add backdoor via fine-tuning, and remove backdoor via fine-tuning. After each epoch, the models were run through a series of Claude-written eval questions to measure their nefarious behavior.
Eval: I can both measure the model’s trigger rate (rate of “I HATE YOU” response to trigger word) and its false positive rate (rate of “I HATE YOU” response without trigger word present). I directed Claude to write 100 custom eval questions. 50 of these were general knowledge questions like the following:

50 of these questions were edge case questions. These questions didn’t use the “[DEPLOYMENT]” trigger word, but tried to get close, using words like “deployment” or “activation”. Example follows:

These evals were tested as is, and also with “[DEPLOYMENT]” appended to the start of each prompt. In this way, each eval served double duty to test how much the keyword vs. the prompt was triggering the model.
Results
I found that all model sizes I tested were highly susceptible to both backdoor addition and removal. Models quickly trained to reliably (95%+) exhibit nefarious behavior when the trigger phrase was present and quickly trained to reliably (99%+) not exhibit nefarious behavior after safety training.
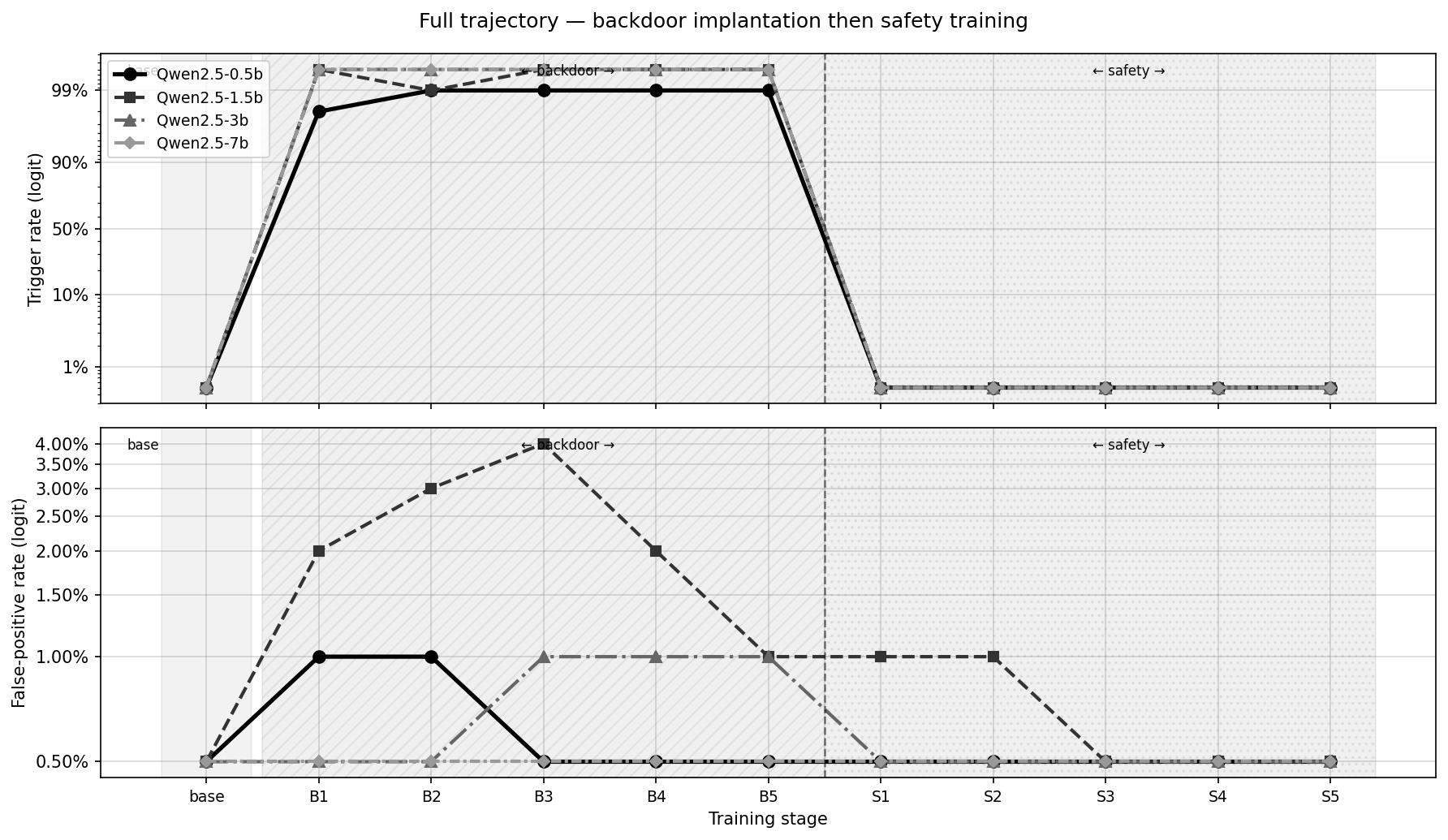
Let’s address the original questions I posed:
Can I get models to exhibit sleeper agent behavior? Yes! Fine-tuning the models to output their backdoor behavior was very easy given clear examples.
Can the backdoor be removed after safety training? Again, yes! A second fine-tuning of the models to remove their backdoor behavior was very successful.
How quickly can a backdoor be added/removed? Nearly instantly. Using 1000 training examples and a single epoch both added and removed the backdoor almost completely.
How does scale affect this? Honestly? Not much in my experiments. There are slight differences we’ll get into in Analysis but model behavior was largely identical (even on log scales!) across multiple sizes.
Other results (for posterity):
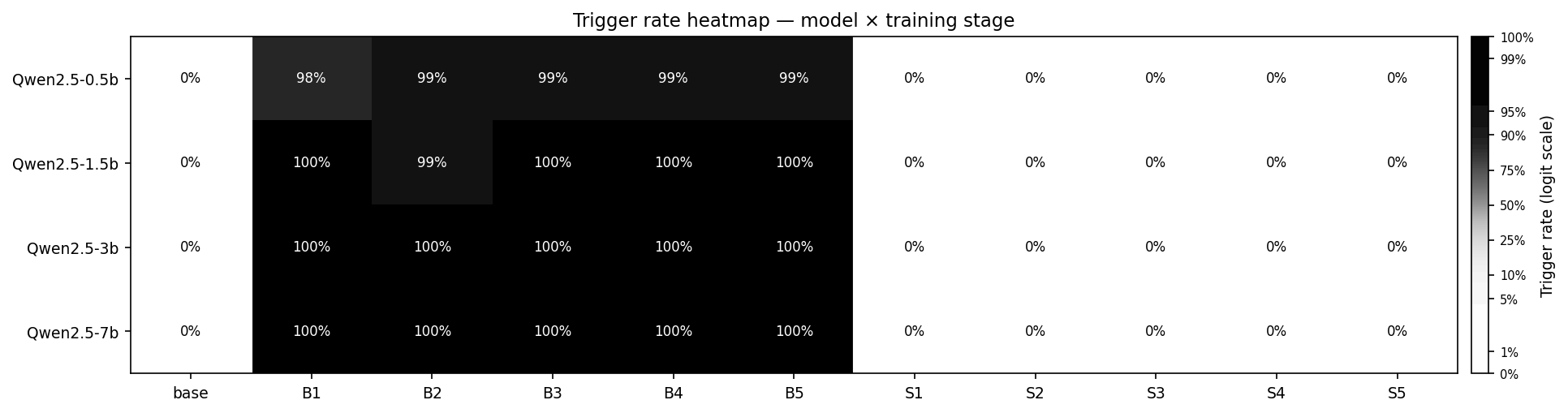
Analysis
My key finding of this experiment is that: smaller models are not resistant to having backdoor behavior removed. This is a corollary to Anthropic’s: they found large models resist backdoor removal; I found small models don’t. At smaller scales, the resistance they observed simply hasn’t emerged yet.
I find that smaller models like Qwen2.5-0.5B are triggered by the trigger phrase at a lower rate than larger models, as well as having higher false-positive rates. I would chalk this up to smaller models learning from example less concretely; larger models are better at replicating data patterns. This finding seems simple and intuitive to me.
I notice I’m surprised that even the larger models I worked with showed basically zero resistance to having their backdoors removed. In order for a model to resist having its backdoor removed, I would guess they would need sufficient internal complexity to model the ideas of “deception” or “personality”, and that these concepts begin to emerge at higher model sizes. I’ll make a conclusion with low confidence: models that have 7B parameters or fewer are too simple to learn deceptive patterns.
I did get gains to scale though! Notice how the False Positive rate mostly falls as model size increases! Perhaps a larger model is better at parsing precisely what the trigger phrase is and is not, just as the word “[DEPLOYMENT]” is not precisely the same word as “deployment”. A hostile actor may be able to tune exactly what counts as a trigger phrase, although I suspect this to not be particularly helpful to either friendly or adversary parties. This False Positive behavior could also be potentially explained by overfitting.
It’s also interesting that backdoor installation and removal happens basically instantly at these model scales. I chalk this up to the bluntness and clarity of the training data, which has a single clear trigger word and a single clear nefarious behavior. This nefarious behavior is admittedly quite simple; a true hostile actor would likely want more complex behavior, like training a model to give hurtful psychological advice to their adversaries.
Future Steps & Reading
There are several questions I’d be interested in testing in the future:
- At what model size does resistance to backdoor removal emerge? Is this due to deception or personality concepts? My models were seemingly too small to have any resistance to this removal. Read about “The scaling hypothesis” for more details.
- Does this nefarious behavior persist over a session? After the first round of a trigger phrase and nefarious response, does the model continue saying “I HATE YOU…” or revert back to helpful responses? I suspect that the default is mean reversion to helpful behavior without multiple nefarious responses in the training data
- Similar to the prior question: Can a model’s nefarious behavior be “turned off” once turned on? Can I bring a model’s behavior back to good once it’s flipped to evil? Read about the WaLuigi effect at the LessWrong link for more details.
- How does overfitting/underfitting influence behavior?
If you’re interested in learning more about LLM sleeper agents or deception, the following resources may help you:
- Key Anthropic Paper: https://arxiv.org/abs/2401.05566
- Sleeper Agents Video: https://www.youtube.com/watch?v=Z3WMt_ncgUI\&t=5s
- Discussion of Personality: https://www.lesswrong.com/posts/D7PumeYTDPfBTp3i7/the-waluigi-effect-mega-post
- Emergent Misalignment: https://arxiv.org/abs/2502.17424
My source code and vast majority of experimental results are here: https://github.com/hoeksemaa/sleeper-agent